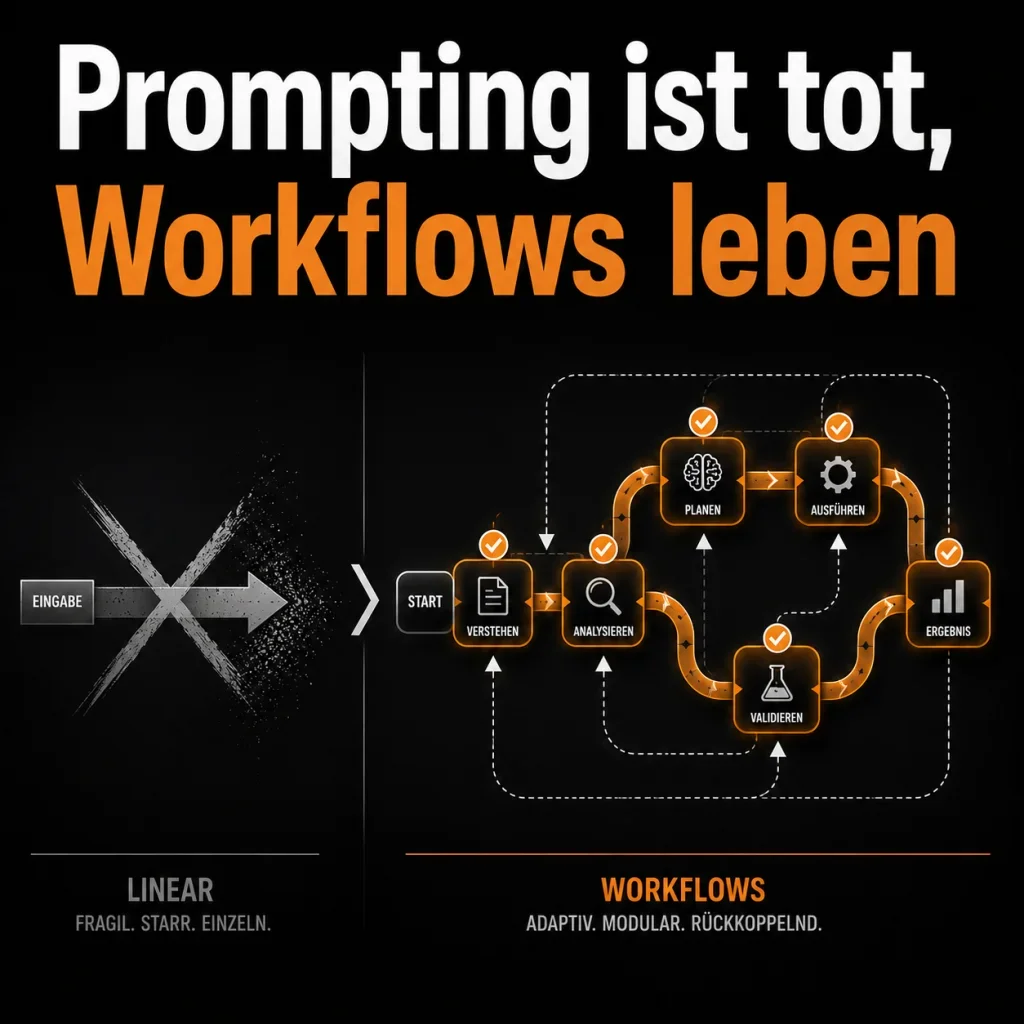
Warum einzelne Prompts an ihre Grenzen stoßen und wie Pipelines sie ersetzen
Ein guter Prompt liefert eine gute Antwort. Eine Pipeline liefert ein fertiges Ergebnis. Der Unterschied ist strukturell.
Wer KI für echte Aufgaben einsetzt, merkt das schnell: Ein einzelner Prompt ist gut fürs Denken. Für Produktionssysteme reicht er nicht. Nicht weil die Modelle zu schwach wären, sondern weil komplexe Aufgaben aus mehreren Schritten bestehen, Fehler Wiederholbarkeit erfordern und Outputs validiert werden müssen, bevor sie irgendwo einfließen.
Der Umstieg von Einzelprompts zu Pipelines ist keine Optimierung. Es ist eine andere Art zu denken.
Das Skalierungsproblem des Einzelprompts
Stellen wir uns vor, aus einer Kundenbewertung soll ein strukturierter Datensatz entstehen: Sentiment, Themen, Handlungsbedarf, zugewiesenes Team. Ein einziger Prompt kann das leisten – manchmal. Das Problem ist das Wort „manchmal”.
Was bei Einzelprompts schiefgeht:
- Kontextkollaps. Je mehr Information du in einen Prompt packst, desto mehr verliert das Modell den Faden. Ein einzelner Prompt, der fünf Dinge gleichzeitig tun soll, macht alle fünf Dinge mittelmäßig.
- Kein Fehlerhandling. Wenn das Modell unerwarteten Output produziert – falsches Format, leere Felder, halluzinierte Daten – hast du keine Schicht, die das abfängt.
- Kein State. Einzelprompts sind zustandslos. Wenn Schritt 2 das Ergebnis von Schritt 1 braucht, musst du es komplett neu in den Prompt gießen.
- Nicht wartbar. Ein monolithischer 800-Wörter-Prompt, der alles gleichzeitig macht, ist schwer zu debuggen und noch schwerer anzupassen.
Die architektonische Verschiebung
Der Übergang vom Prompt zur Pipeline ist vergleichbar mit dem Übergang von einem langen Bash-Einzeiler zu strukturiertem Code: man bekommt Lesbarkeit, Wartbarkeit und die Möglichkeit, Teile unabhängig zu testen.
[Einzelprompt] alles auf einmal, kein Fehlerhandling
↓
[Sequenzielle Pipeline] Schritt für Schritt, mit State
↓
[Strukturierte Pipeline] Input → Verarbeitung → Validation → Output
↓
[Orchestrierter Workflow] Conditional Steps, Parallelisierung, MonitoringEine Pipeline zerlegt eine komplexe Aufgabe in Schritte. Jeder Schritt hat eine klar definierte Eingabe und Ausgabe. Schritte können KI-Calls sein, aber auch klassischer Code: ein API-Lookup, eine Datenbankabfrage, eine Schema-Validation.
Das ist der entscheidende Punkt: Eine KI-Pipeline ist kein LLM-Wrapper. Sie ist ein System, in dem LLM-Calls Schritte sind.
Bausteine einer Pipeline
Input: Aufbereitung schlägt Prompt-Länge
Der häufigste Fehler beim Übergang zu Pipelines: Den Input unverändert in den ersten LLM-Schritt zu kippen. Guter Pipeline-Input ist normalisiert und angereichert.
type PipelineInput = {
rawText: string;
metadata: {
sourceType: 'email' | 'review' | 'support-ticket';
language: string;
timestamp: string;
};
};
async function prepareInput(raw: string, sourceType: string): Promise<PipelineInput> {
return {
rawText: raw.trim().slice(0, 4000), // sicheres Limit
metadata: {
sourceType: sourceType as PipelineInput['metadata']['sourceType'],
language: await detectLanguage(raw),
timestamp: new Date().toISOString(),
},
};
}Sprache erkennen, Text kürzen, Format normalisieren: Das ist klassischer Code, kein LLM-Call. Je sauberer der Input, desto konsistenter der Output.
Verarbeitung: Ein Schritt, eine Aufgabe
Die wichtigste Regel: Jeder LLM-Schritt macht genau eine Sache.
// Schlecht: ein Prompt für alles
const prompt = `
Extrahiere das Sentiment, fasse zusammen, identifiziere Themen,
weise einem Team zu und schlage drei Maßnahmen vor.
`;
// Gut: ein Schritt pro Aufgabe
const sentiment = await extractSentiment(text);
const topics = await extractTopics(text);
const summary = await summarize(text, topics);
const assignment = await assignTeam(topics, sentiment);Das erscheint aufwändiger, ist aber wartbarer: Du kannst jeden Schritt einzeln testen, einzeln ändern und einzeln überwachen.
const [sentiment, topics] = await Promise.all([
extractSentiment(text),
extractTopics(text),
]);
const summary = await summarize(text, { sentiment, topics });Validation: Der wichtigste Schritt, den die meisten weglassen
LLMs produzieren Text. Dein System braucht Daten. Zwischen Text und Daten liegt die Validation.
import { z } from 'zod';
const SentimentSchema = z.object({
score: z.number().min(-1).max(1),
label: z.enum(['positive', 'neutral', 'negative']),
confidence: z.number().min(0).max(1),
});
async function extractSentiment(text: string) {
const response = await llm.generate({
system: 'Du gibst Sentiment als JSON zurück: { score: -1 bis 1, label: ..., confidence: 0-1 }',
user: text,
});
const parsed = JSON.parse(response.text);
return SentimentSchema.parse(parsed); // wirft ZodError bei ungültigem Output
}Zod-Validation direkt nach jedem LLM-Call ist das Minimum. Wenn das Modell Unsinn zurückgibt, scheitert die Validation – und du kannst reagieren.
Fehlerbehandlung und Retry-Logik
Ohne Fehlerhandling ist eine Pipeline brüchiger als ein Einzelprompt, weil mehr Schritte auch mehr Fehlerpunkte bedeuten. Die Lösung ist explizites Handling auf drei Ebenen:
Ebene 1: Retry bei transienten Fehlern
async function withRetry<T>(
fn: () => Promise<T>,
maxAttempts = 3,
delayMs = 1000,
): Promise<T> {
for (let attempt = 1; attempt <= maxAttempts; attempt++) {
try {
return await fn();
} catch (err) {
if (attempt === maxAttempts) throw err;
await new Promise((r) => setTimeout(r, delayMs * attempt));
}
}
throw new Error('Unreachable');
}
const sentiment = await withRetry(() => extractSentiment(text));Rate-Limiting, Timeouts und gelegentliche Modell-Fehler sind transient. Drei Versuche mit exponentiellem Backoff lösen 90 % dieser Fälle.
Ebene 2: Fallback bei persistenten Fehlern
async function extractSentimentWithFallback(text: string) {
try {
return await withRetry(() => extractSentiment(text));
} catch {
// Fallback: regelbasierte Heuristik statt LLM
return heuristicSentiment(text);
}
}Nicht jeder Schritt braucht einen Fallback. Aber kritische Schritte – besonders die, die das gesamte Downstream-Verhalten beeinflussen – sollten einen haben.
Ebene 3: Dead Letter Queue für vollständige Pipeline-Fehler
Wenn eine Pipeline-Instanz nach allen Retries fehlschlägt, landet sie in einer Dead Letter Queue für manuelles Review. Das ist kein LLM-Problem, das ist Systemarchitektur.
async function runPipeline(input: PipelineInput) {
try {
return await executePipeline(input);
} catch (err) {
await deadLetterQueue.push({
input,
error: err instanceof Error ? err.message : String(err),
timestamp: new Date().toISOString(),
});
throw err; // weiter nach oben propagieren
}
}Praktische Beispiele
Beispiel 1: Content-Pipeline
Eine Pipeline, die aus einem Thema und Zielgruppe einen vollständigen Blog-Artikel produziert:
Der entscheidende Schritt: Abschnitte parallel schreiben. Bei einem zehnteiligen Artikel bedeutet das Promise.all über zehn LLM-Calls – die Latenz bleibt die des langsamsten Calls, nicht die Summe aller.
Beispiel 2: Code-Generations-Pipeline
interface CodeRequest {
description: string;
language: 'typescript' | 'python' | 'rust';
existingCode?: string;
}
async function generateCode(request: CodeRequest) {
// Schritt 1: Requirements klären
const clarifiedReqs = await clarifyRequirements(request.description);
// Schritt 2: Code generieren
const rawCode = await generateFromRequirements(clarifiedReqs, request.language);
// Schritt 3: Review & Verbesserungen
const review = await reviewCode(rawCode, clarifiedReqs);
// Schritt 4: Finale Version
const finalCode = review.issues.length > 0
? await applyReviewFeedback(rawCode, review.issues)
: rawCode;
// Schritt 5: Validation (syntaktisch prüfbar)
await validateSyntax(finalCode, request.language);
return finalCode;
}Das Muster „Review & ggf. Überarbeiten” ist für Code besonders wertvoll: Das Modell überprüft seinen eigenen Output mit einem spezifischeren Blick. Das verbessert die Qualität messbar, weil Reviewer-Perspektive und Autoren-Perspektive getrennt sind.
Beispiel 3: Datenanalyse-Pipeline
async function analyzeCustomerFeedback(feedbacks: string[]) {
// Schritt 1: Parallel alle Bewertungen strukturieren
const structured = await Promise.all(
feedbacks.map((text) =>
withRetry(() => structureFeedback(text))
)
);
// Schritt 2: Aggregation (kein LLM, klassischer Code)
const aggregated = aggregateByTopic(structured);
// Schritt 3: Interpretation (LLM, hat jetzt saubere Daten)
const insights = await interpretAggregated(aggregated);
// Schritt 4: Handlungsempfehlungen
const recommendations = await generateRecommendations(insights);
return { structured, aggregated, insights, recommendations };
}Der Trick ist Schritt 2: Aggregation ist kein LLM-Job. Zählen, gruppieren, sortieren – das macht normaler Code besser, schneller und deterministisch. Der LLM bekommt im nächsten Schritt nicht rohe Texte, sondern sauber aggregierte Zahlen.
Orchestrierungstools
Für einfache sequenzielle Pipelines reicht TypeScript oder Python mit async/await. Ab einer bestimmten Komplexität lohnen sich spezialisierte Tools:
LangChain / LangGraph – weit verbreitet, für Python und TypeScript. LangGraph eignet sich für stateful, nicht-lineare Workflows mit Schleifen und Verzweigungen. Viel Abstraktion, manchmal zu viel.
Temporal – nicht KI-spezifisch, aber exzellent für langlebige Workflows mit Durability und automatischen Retries. Gut wenn Pipelines über Stunden oder Tage laufen können.
Inngest / Trigger.dev – serverlos, event-basiert. Gut für Pipelines, die durch externe Events angestoßen werden (Webhook → Pipeline-Start).
Eigenes System – oft unterschätzt. Für gut abgegrenzte Pipelines ist ein schlankes eigenes System wartbarer als ein Framework mit steiler Lernkurve.
Wann eine Pipeline zu viel ist
Nicht jede KI-Aufgabe braucht eine Pipeline. Ein Einzelprompt ist die richtige Wahl wenn:
- Die Aufgabe einfach und klar begrenzt ist
- Der Output direkt menschlich geprüft wird (kein Downstream-System)
- Du explorativ arbeitest, nicht produktiv
- Latenz wichtiger ist als Zuverlässigkeit
Eine Pipeline ist die richtige Wahl wenn:
- Der Output in andere Systeme fließt
- Fehler silent failures verursachen würden
- Die Aufgabe aus mehr als zwei unabhängigen Schritten besteht
- Du Monitoring und Debugging brauchst
- Das System von anderen Menschen gewartet wird
Einordnung
Die Reise von Einzelprompts zu Pipelines ist keine Frage des Modells oder des Prompt-Handwerks. Es ist eine Frage der Systemarchitektur.
Pipelines bringen das, was Softwareentwicklung in den letzten Jahrzehnten gelernt hat, in den KI-Kontext: Separation of Concerns, Testbarkeit, Fehlerhandling, Observability. Ein LLM-Call ist eine externe Abhängigkeit – nicht anders als eine Datenbank oder ein API-Call. Er sollte auch so behandelt werden.
Wer das verinnerlicht, baut robustere Systeme. Nicht weil die Prompts besser werden, sondern weil das Drumherum professioneller wird.