Puppeteer, wkhtmltopdf, LaTeX – und was der Typst-basierte Rust-Ansatz anders macht
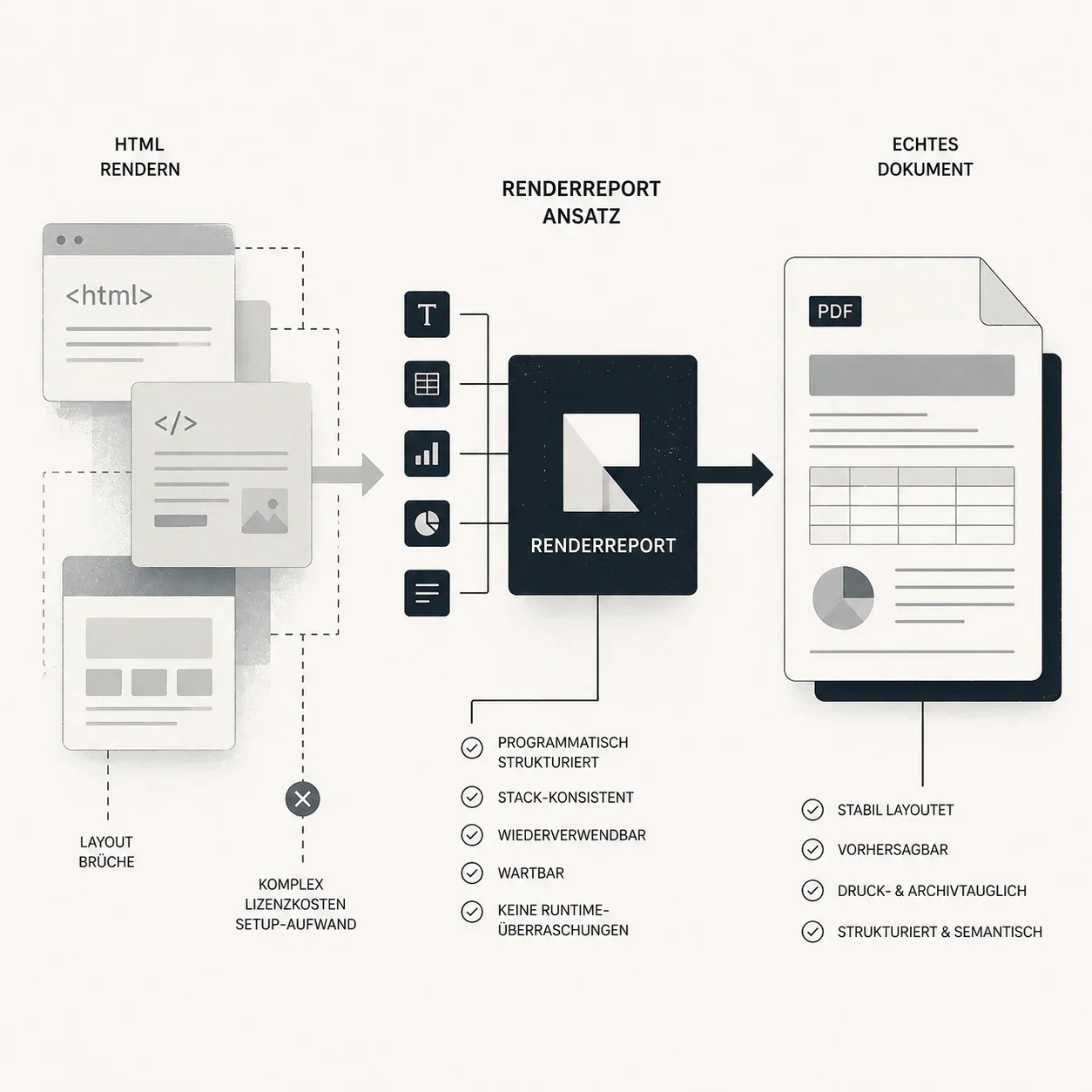
Der Ausgangspunkt war konkret: PDF-Berichte erzeugen, die wirklich strukturiert sind – kein HTML, das in ein PDF gerendert wird, sondern ein Dokument, das als Dokument gedacht ist. Was vorher zur Verfügung stand, waren kommerzielle Bibliotheken in anderen Ökosystemen, meist C#. Die haben funktioniert – aber nicht im Stack, den ich tatsächlich nutze, und mit einem Lizenz- und Einrichtungsaufwand, der für jedes neue Projekt von vorn beginnt.
Also: anderer Weg. Wer dabei anfängt zu recherchieren, stößt auf die üblichen Verdächtigen.
Die üblichen Verdächtigen
Puppeteer / Playwright: HTML zu PDF über einen headless Browser. Funktioniert gut für Web-Content, bringt aber 100–200 MB an Chromium mit, hat flakige Rendering-Unterschiede je nach Systemkonfiguration und skaliert schlecht, wenn viele PDFs parallel erzeugt werden müssen.
wkhtmltopdf: Ein älteres Tool mit ähnlichem Ansatz. Stabiler als Puppeteer für einfache Dokumente, aber seit Jahren nicht mehr aktiv entwickelt und mit bekannten CSS-Inkompatibilitäten.
LaTeX: Präzise, professionell und vollständig – aber auch steil in der Lernkurve. Jede Kleinigkeit im Layout braucht LaTeX-Syntax. Ein einfaches zweispaltiges Layout ist nicht schwer, ein komplexes Reporting-Template ist ein Projekt für sich.
ReportLab / WeasyPrint (Python): Gute Optionen für Python-Ökosysteme, aber eine zusätzliche Runtime-Abhängigkeit für Rust- oder Node-Projekte.
DevExtreme Reporting: Das war über lange Zeit mein tatsächlich genutzter Weg – ein kommerzielles Reporting-Tool von DevExpress, das PDF-Generierung mit einem breiten Komponenten-Angebot verbindet. Funktioniert gut in dem Stack, für den es gedacht ist. Wer außerhalb davon arbeitet, erkauft sich die Funktionalität mit Lizenzkosten und einer Ökosystem-Abhängigkeit, die bei jedem neuen Projekt neu anfällt.
Keiner dieser Ansätze ist falsch. Aber jeder hat spürbare Reibung – entweder durch externe Abhängigkeiten, fehlende Typsicherheit oder einen Rendering-Prozess, der nicht zum eigentlichen Stack passt.
Was Typst als Basis verändert
renderreport basiert auf Typst, einem modernen Textsatzsystem, das als Rust-Library eingebettet werden kann. Den Weg dorthin würde ich ehrlich als Glücksfund beim Recherchieren beschreiben – Typst stand nicht von Anfang an auf einer Shortlist, sondern tauchte beim Durcharbeiten der Alternativen auf und passte in mehreren Punkten auf das, was gesucht wurde. Das ist der entscheidende Unterschied zu anderen Ansätzen.
Typst ist kein externer Prozess, der über CLI aufgerufen wird. Es ist eine Library, die sich in den Build-Prozess integriert – kein separater Server, kein Subprocess, keine Laufzeit-Abhängigkeit, die separat installiert werden muss.
Die Rendering-Geschwindigkeit ist ein direktes Ergebnis davon: Typst kompiliert Dokumente in Millisekunden, nicht in Sekunden. Für einen einzelnen Report ist das akademisch. Für einen Batch von 50 Reports oder einen PDF-Endpoint unter Last macht es den Unterschied – und ein Chromium-Prozess, der für jeden Request neu gestartet werden müsste, wäre in diesem Szenario kein realistischer Vergleich.
Wie der Flow aussieht
Der gesamte Prozess läuft in derselben Rust-Binary:
Was renderreport konkret mitbringt
Die Library ist um Komponenten gebaut, nicht um leere Seiten. Wer einen Audit-Report braucht, startet nicht bei null:
- ScoreCard & Gauge für Metriken mit visueller Score-Anzeige und konfigurierbaren Schwellenwerten
- Finding & SpotlightCard für strukturierte Befunde mit Severity-Level (critical, info, feature, opportunity)
- AuditTable & Crosstab für Datentabellen und dynamische Pivot-Tabellen mit Aggregation
- Charts & Sparklines: Bar, Line, Pie, Area, Scatter, Radar – plus inline Sparklines und TrendTiles
- Timeline & ProcessFlow für Projektphasen, Meilensteine und RoadmapBlocks
- Barcode & QR in 11 Formaten: QR-Code, Data Matrix, EAN-13, Code128, PDF417
- Layout-Primitives: Section, Grid, Columns mit Ratio, FlowGroup, PageBreak
Das sind keine Styling-Klassen. Es ist eine Komponenten-API mit Type-Safety: Wer eine FindingCard einbindet, bekommt Compile-Zeit-Fehler, wenn Pflichtfelder fehlen. Reports werden Teil des Codes, nicht String-Templates – der Unterschied zur Template-Engine (Handlebars, EJS) zeigt sich spätestens dann, wenn eine Report-Struktur refaktoriert werden muss.
Ein minimales Beispiel, das zeigt wie sich das anfühlt:
use renderreport::{Report, AuditPattern, FindingCard, Severity};
let report = Report::new(AuditPattern::default())
.title("Security Audit Q1 2026")
.finding(
FindingCard::new("Fehlende Rate-Limitierung")
.severity(Severity::Critical)
.description("Der /api/auth Endpoint hat kein Rate-Limiting.")
.recommendation("Token Bucket mit max. 10 req/min einführen."),
)
.build()?;
std::fs::write("audit.pdf", report.to_pdf()?)?;Kein Template-String, keine Platzhalter, keine Laufzeit-Fehler für fehlende Felder. Der Compiler prüft das.
Drei Report-Patterns als Ausgangspunkt
renderreport liefert drei vorgefertigte Report-Patterns mit, die für typische Anwendungsfälle sofort einsatzbereit sind:
Audit-Report: Executive Summary, Findings nach Severity sortiert, Maßnahmenplan mit Aufwand und Scope, technische Detailblöcke.
Business-Report: KPI-Dashboard, Trendanalyse mit Charts, Kommentarspalten, Management-Summary.
Technischer Bericht: Spezifikationen, Tabellen, Prozessdiagramme, Anhänge.
Jedes Pattern ist ein Startpunkt, kein Constraint – alle Komponenten sind kombinierbar.
Wann dieser Ansatz passt
Nicht für jeden Use Case. renderreport ist eine technische Library, kein No-Code-Tool. Die Stärken liegen konkret bei:
Reporting-Pipelines: Wer aus strukturierten Daten (JSON, Datenbankabfragen, API-Responses) regelmäßig PDFs erzeugen muss – monatliche Reports, automatische Audits, Export-Features in Software-Produkten.
Deterministisches Rendering: Typst produziert bei identischer Eingabe identische Ausgabe – unabhängig vom Host, Betriebssystem oder installierten Schriftarten. Das ist für Compliance, Audits und automatisierte Reports kein Nice-to-have. Browser-basiertes Rendering (Puppeteer, wkhtmltopdf) ist das nicht: CSS verhält sich je nach Engine unterschiedlich, Fonts fehlen in CI-Umgebungen, Seitenumbrüche verschieben sich.
Edge-Deployments und CI/CD: Kein Chromium bedeutet minimale Container-Images, keine Sandbox-Konfigurationen, keine Probleme mit Headless-Display-Servern in CI. Die Binary bringt alles mit. Das funktioniert auf Fly.io, in GitHub Actions oder in einem Cloudflare Worker-ähnlichen Setup ohne zusätzliche Konfiguration.
Rust-Projekte, die PDF-Output brauchen: Die Integration ist nativ, kein Subprocess, kein IPC-Overhead.
Für einmalige Dokumente, Marketing-Material oder Inhalte, die starke Design-Freiheit brauchen, ist ein grafisches Tool oder ein HTML-zu-PDF-Workflow oft schneller am Ziel. Der renderreport-Ansatz zahlt sich aus, wo Konsistenz, Geschwindigkeit und Wartbarkeit wichtig sind – nicht bei der einmaligen Präsentation.
Ein Hinweis aus der Praxis: Auch mit renderreport brauchen Report-Definitionen oft Nacharbeit. Layouts wollen angepasst werden, Datenstrukturen passen nicht immer auf Anhieb ins Template. Das Schöne dabei ist: Die PDF, die am Ende entsteht, ist tatsächlich vernünftig strukturiert – kein nachträgliches Reparieren im Viewer, keine Schriftarten, die auf einem anderen System fehlen, keine Rendering-Überraschungen zwischen Entwicklung und Produktion.
Die Grenzen gehören dazu: Es gibt kein WYSIWYG. Design-Iteration läuft über Code, nicht über einen visuellen Editor. Wer Layout-Entscheidungen schnell im Browser ausprobieren will, ist mit HTML-zu-PDF zunächst schneller. Typst ist außerdem noch ein junges Ökosystem – nicht jede Anforderung ist fertig gelöst, und das Community-Angebot an Vorlagen ist kleiner als bei LaTeX. Das ist kein Blocker, aber eine realistische Einschätzung für Projekte, die sehr spezifische Typografie-Anforderungen haben.