Function Calling erlaubt Sprachmodellen, strukturierte API-Anfragen auszulösen — ohne Middleware, ohne fragiles Prompt-Parsen. Wie Mistral das umsetzt und wann es sich lohnt.
SerieMistral & Vibe CLI
Teil 17 von 19
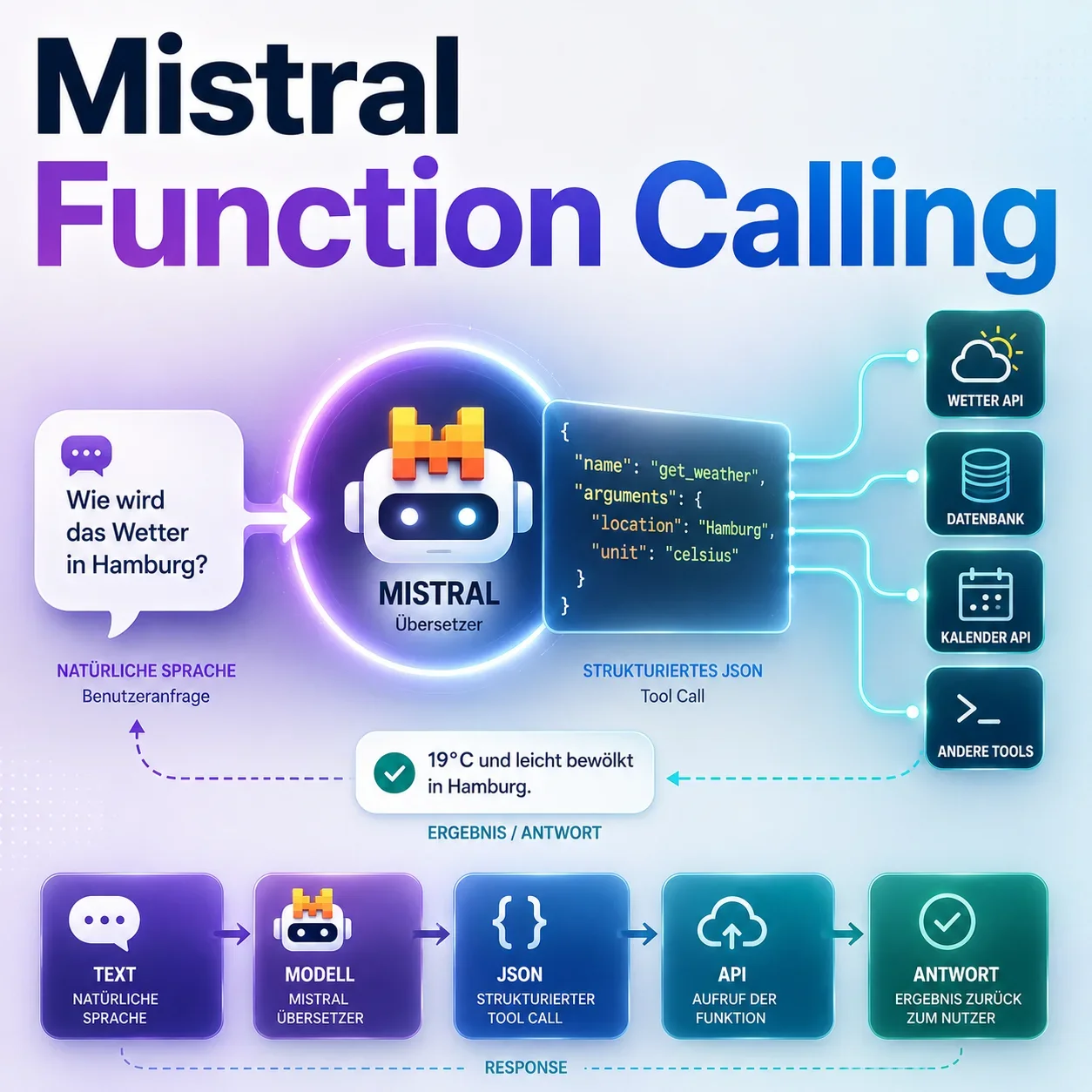
Sprachmodelle können sprechen — aber lange nicht zuverlässig handeln. Das Kernproblem: Wenn ein Modell auf eine Frage antwortet, produziert es Text. Aus diesem Text eine strukturierte API-Anfrage zu destillieren erfordert entweder fragiles Regex-Parsen oder einen weiteren Verarbeitungsschritt. Function Calling löst dieses Problem direkt im Modell. Statt Text zu produzieren, gibt das Modell ein strukturiertes JSON-Objekt aus — exakt nach dem Schema, das die API erwartet.
Mistral hat Function Calling als First-Class-Feature in sein API-Design integriert. Das Modell entscheidet selbst, ob und welche Funktion es aufruft, welche Parameter es befüllt und wann es antwortet — ohne, dass der Aufrufer Text parsen muss.
Was Function Calling eigentlich ist
Der Begriff ist etwas irreführend: Das Modell „ruft” keine Funktionen auf. Es gibt eine strukturierte Entscheidung zurück: „Ich würde jetzt diese Funktion mit diesen Parametern aufrufen wollen.” Die eigentliche Ausführung liegt beim aufrufenden Code.
Das Protokoll sieht ungefähr so aus:
import mistralai
client = mistralai.Mistral(api_key="...")
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Aktuelles Wetter für einen Ort abrufen",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "Stadt und Land, z.B. 'Berlin, Deutschland'"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"]
}
},
"required": ["location"]
}
}
}
]
response = client.chat.complete(
model="mistral-large-latest",
messages=[{"role": "user", "content": "Wie wird das Wetter heute in Hamburg?"}],
tools=tools,
tool_choice="auto"
)Das Modell analysiert die Anfrage, erkennt dass get_weather passt, und gibt statt Freitext ein strukturiertes Tool-Call-Objekt zurück:
{
"role": "assistant",
"tool_calls": [
{
"id": "call_abc123",
"type": "function",
"function": {
"name": "get_weather",
"arguments": "{\"location\": \"Hamburg, Deutschland\", \"unit\": \"celsius\"}"
}
}
]
}Jetzt kommt der aufrufende Code: Die Anwendung führt den echten API-Aufruf durch, fügt das Ergebnis als Tool-Message in den Verlauf ein, und fragt das Modell erneut — das formuliert dann die natürlichsprachliche Antwort.
Der vollständige Zyklus
In der Praxis ist Function Calling ein Zwei-Phasen-Protokoll.
Phase 1 — Modell entscheidet: Das Modell liest die Nutzernachricht und den verfügbaren Tool-Katalog. Es gibt entweder eine direkte Antwort oder einen Tool-Call zurück.
Phase 2 — Anwendung führt aus und informiert: Die Anwendung führt den Tool-Call aus, hängt das Ergebnis an den Gesprächsverlauf und lässt das Modell darauf reagieren.
import json
def handle_conversation(user_message: str) -> str:
messages = [{"role": "user", "content": user_message}]
response = client.chat.complete(
model="mistral-large-latest",
messages=messages,
tools=tools,
tool_choice="auto"
)
message = response.choices[0].message
# Kein Tool-Call → direkte Antwort
if not message.tool_calls:
return message.content
# Tool-Call → ausführen, Ergebnis zurückgeben
messages.append(message)
for tool_call in message.tool_calls:
result = execute_tool(
tool_call.function.name,
json.loads(tool_call.function.arguments)
)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": json.dumps(result)
})
# Zweiter Aufruf: Modell formuliert Antwort auf Basis des Ergebnisses
final_response = client.chat.complete(
model="mistral-large-latest",
messages=messages
)
return final_response.choices[0].message.contentDer entscheidende Punkt: execute_tool ist normale Anwendungslogik — eine REST-Anfrage, ein Datenbankaufruf, ein Dateisystem-Zugriff. Das Modell weiß nicht, wie die Ausführung funktioniert. Es liefert nur den Intent.
Wann tool_choice steuern
Mistral bietet vier Modi für tool_choice:
"auto"— Modell entscheidet selbst (Standard)"any"— Modell muss mindestens einen Tool-Call machen"none"— Kein Tool-Call, direkte Antwort{"type": "function", "function": {"name": "..."}}— Erzwingt eine bestimmte Funktion
Für Automatisierungsszenarien ist "any" interessant: Der Workflow erzwingt einen Tool-Call, ohne zu spezifizieren, welchen. Das Modell wählt — aber es kommt garantiert strukturierter Output zurück, kein Freitext.
Mehrere Tools gleichzeitig
Mistral unterstützt parallele Tool-Calls innerhalb einer Antwort. Bei komplexeren Anfragen ruft das Modell mehrere Funktionen gleichzeitig auf:
tools = [
{"type": "function", "function": {"name": "get_weather", ...}},
{"type": "function", "function": {"name": "get_news", ...}},
{"type": "function", "function": {"name": "get_calendar", ...}},
]
# Anfrage: "Was soll ich heute planen?"
# Modell ruft get_weather, get_news und get_calendar parallel aufDas verkürzt Latenz erheblich: Statt drei sequenzieller Runden laufen alle Abfragen parallel — der Orchestrator führt sie gleichzeitig aus und gibt alle Ergebnisse gesammelt zurück.
Praktisches Beispiel: Bestellstatus-Bot
Ein konkreter Anwendungsfall: Ein interner Support-Bot soll Bestelldaten aus dem ERP abrufen, ohne dass Mitarbeitende selbst im System suchen müssen.
tools = [
{
"type": "function",
"function": {
"name": "get_order_status",
"description": "Bestellstatus aus dem ERP abrufen",
"parameters": {
"type": "object",
"properties": {
"order_id": {"type": "string", "description": "Bestellnummer"},
"customer_id": {"type": "string", "description": "Kundennummer (optional)"}
},
"required": ["order_id"]
}
}
},
{
"type": "function",
"function": {
"name": "list_orders_by_customer",
"description": "Alle Bestellungen eines Kunden auflisten",
"parameters": {
"type": "object",
"properties": {
"customer_id": {"type": "string"},
"status_filter": {
"type": "string",
"enum": ["all", "open", "shipped", "cancelled"]
}
},
"required": ["customer_id"]
}
}
}
]Das Modell entscheidet kontextabhängig: „Zeig Bestellung 4711” → get_order_status. „Welche offenen Bestellungen hat Kunde XY?” → list_orders_by_customer. Die Mitarbeitenden tippen natürliche Sprache — darunter läuft saubere API-Logik.
Typsicherheit über JSON Schema
Die parameters-Definition folgt JSON Schema. Das ermöglicht präzise Validierung auf Modell-Seite:
"parameters": {
"type": "object",
"properties": {
"date": {
"type": "string",
"format": "date",
"description": "Datum im Format YYYY-MM-DD"
},
"priority": {
"type": "integer",
"minimum": 1,
"maximum": 5
},
"tags": {
"type": "array",
"items": {"type": "string"},
"maxItems": 10
}
},
"required": ["date", "priority"]
}Das Modell hält sich an diese Constraints. Kein Freitext-Parsen, kein Typkonvertieren — die Argumente kommen bereits im richtigen Format an.
Structured Output als Ergänzung
Neben Function Calling bietet Mistral auch Structured Output — ein verwandtes, aber eigenständiges Feature. Statt Tool-Calls zu definieren, gibt man ein JSON Schema direkt vor und das Modell antwortet garantiert schema-konform.
Der Unterschied: Structured Output ersetzt keine API-Calls. Es strukturiert die Antwort selbst — zum Beispiel wenn aus einem Freitext-Dokument Felder extrahiert werden sollen, ohne dass ein externer Service aufgerufen wird.
Die beiden Features ergänzen sich: Function Calling für Aktionen, Structured Output für Extraktion.
Grenzen und Fallstricke
Function Calling löst das strukturierte Output-Problem. Es löst nicht das Verständnis-Problem.
Das Modell kann falsch interpretieren, welche Funktion gemeint ist — besonders wenn Beschreibungen ähnlich oder unklar sind. Die description-Felder sind entscheidend: Je präziser, desto besser das Routing. Vage Beschreibungen wie „Daten abrufen” führen zu Fehlaufrufen.
Ein weiterer Fallstrick: Das Modell gibt Arguments als JSON-String zurück, nicht als geparste Struktur. json.loads(tool_call.function.arguments) ist daher kein Komfortaufruf, sondern notwendig — und kann bei beschädigtem Output fehlschlagen. Validierung vor der Ausführung ist sinnvoll.
Außerdem: Das Modell hat keinen Zugriff auf Laufzeitdaten. Es weiß nicht, ob eine Bestellnummer existiert. Fehlerfälle aus der Tool-Ausführung müssen explizit als Tool-Message zurückgegeben werden, damit das Modell sinnvoll darauf reagiert:
try:
result = erp_api.get_order(order_id)
tool_response = {"status": "success", "data": result}
except OrderNotFound:
tool_response = {"status": "error", "message": f"Bestellung {order_id} nicht gefunden"}Das Modell formuliert daraus eine verständliche Fehlermeldung — aber nur, wenn der Fehler sauber übergeben wird.
Mistral vs. andere Modelle
Die Function-Calling-Implementierung von Mistral ist technisch ähnlich zu OpenAIs Tool-Use-Interface. Wer bereits mit OpenAIs Clients arbeitet, findet das Protokoll weitgehend identisch — intentional, da Mistral API-Kompatibilität als Ziel nennt.
Der praktische Unterschied liegt in Kosten, Latenz und Modellverhalten. mistral-small oder mistral-medium sind bei einfachen Routing-Aufgaben oft ausreichend und günstiger als GPT-4-Klasse-Modelle. Für komplexe mehrstufige Entscheidungen ist mistral-large stabiler.
Ein weiterer Aspekt: Mistral bietet mit La Plateforme eine vollständig in der EU gehostete Option — relevant für Anwendungen mit DSGVO-Anforderungen, bei denen Nutzerdaten die EU nicht verlassen dürfen.
Wann Function Calling sinnvoll ist
Function Calling lohnt sich, wenn Sprachverständnis auf strukturierte Systeme trifft — wenn natürlichsprachliche Eingaben in definierte API-Aufrufe übersetzt werden müssen.
Klassische Szenarien:
- Interne Bots für ERP, CRM, Ticketsysteme — Mitarbeitende fragen, das Modell routet
- Formularausfüllung aus freitext-basierten Anfragen — Modell extrahiert strukturierte Felder
- Workflow-Automatisierung — Modell orchestriert mehrere API-Schritte auf Basis einer Absicht
- Daten-Extraktion aus Dokumenten — Input ist Text, Output ist definiertes Schema
Weniger sinnvoll ist Function Calling, wenn die Eingabe bereits strukturiert ist (dann braucht kein Sprachmodell dazwischen) oder wenn Determinismus kritisch ist — Modellentscheidungen können variieren. Für Kernprozesse mit garantierten Outputs gehört die Entscheidungslogik weiterhin in den Code, nicht ins Modell.
Einordnung
Function Calling ist kein KI-Hype-Feature — es ist eine pragmatische Brücke zwischen Sprachverständnis und Systemintegration. Das Modell übernimmt die Interpretation, der Code übernimmt die Ausführung. Die Grenze bleibt klar.
Für Teams, die bestehende APIs erschließen wollen ohne aufwändige Middleware, ist das ein direkter Ansatz. Die Hürde ist niedrig: Ein JSON-Schema für die vorhandene API, ein Routing-Loop, und das Modell übernimmt das Intent-Matching.