Was sich bewährt hat – und wo die Architektur entscheidet
SerieMCP für Entwickler
Teil 6 von 8
Als das Model Context Protocol 2024/2025 auftauchte, wirkte es für viele wie die fehlende Standardschicht zwischen LLMs und Software. Endlich ein einheitliches Protokoll, über das ein Agent Tools entdecken, aufrufen und kombinieren kann. Die Idee war überzeugend: Ein Modell bekommt strukturierte Beschreibungen von Funktionen und kann sie wie Bausteine nutzen.
Viele Teams gingen deshalb einen sehr direkten Weg: Bestehende APIs wurden einfach als MCP-Tools exportiert. Im ersten Moment funktioniert das. Ein Agent kann plötzlich auf Datenbanken, SaaS-APIs oder interne Systeme zugreifen. Die Integration ist schnell gebaut und beeindruckt in ersten Demos.
2026 zeigt sich allerdings ein klareres Bild: Diese Architektur funktioniert – aber sie skaliert nicht automatisch.
Das Token-Problem hinter großen Tool-Schemata
Ein praktisches Problem wurde in vielen Projekten erst spät sichtbar: Das Context Window ist eine begrenzte Ressource. Jedes Tool, das ein Agent sehen soll, muss im Kontext beschrieben werden – Name, Beschreibung, Parameter-Schema, Rückgabeformat. Das sind alles Tokens. Und sie summieren sich schnell.
Cloudflare hat das Problem anschaulich demonstriert. Ihre öffentliche API enthält über 2500 Endpunkte. Die vollständige OpenAPI-Spezifikation umfasst ungefähr 2 Millionen Tokens. Selbst stark reduzierte Tool-Schemas bleiben noch im Bereich von hunderttausenden Tokens. Für ein LLM bedeutet das: weniger Platz für Reasoning, höhere Kosten pro Request, längere Latenz. Das Modell verbringt dann einen großen Teil seines Kontextfensters damit, Werkzeuge zu lesen, statt Probleme zu lösen.
LLMs schreiben lieber Code
Eine interessante Beobachtung aus mehreren Projekten: LLMs sind oft besser darin, Code zu schreiben, der eine API nutzt, als tausende einzelne Tools aufzurufen. Der Grund ist einfach – Code kann sehr kompakt sein. Ein Modell kann client.invoices.create(...) schreiben, statt ein komplexes Tool mit einem umfangreichen JSON-Schema zu benutzen.
Cloudflare hat daraus einen anderen Ansatz entwickelt. Statt alle Endpunkte als Tools bereitzustellen, kann ein Agent Code generieren, der gegen die API arbeitet. Dieser Code wird dann serverseitig ausgeführt. Der Kontext enthält damit nur eine kleine Runtime, ein API-Client-Interface und Beispielcode. Das reduziert den Token-Footprint drastisch.
Warum manche Teams wieder zu APIs und CLIs greifen
Für viele Aufgaben braucht man kein LLM im Loop. Bulk-Importe, Datensynchronisation, geplante Jobs, deterministische Geschäftslogik – hier sind klassische Integrationen oft effizienter. SDKs, REST-APIs, CLI-Tools, Automations-Pipelines. Ein Agent bringt in solchen Fällen zusätzliche Risiken: Halluzinationen, unnötige Kosten, schwer reproduzierbares Verhalten.
Deshalb sieht man 2026 häufiger eine Trennung der Architekturschichten.
Agentisch vs. deterministisch
Eine praktikable Architektur trennt heute oft zwei Ebenen. Auf der deterministischen Seite läuft alles, was klar definiert ist: Datenimporte, Synchronisationen, API-Integrationen, Batch-Verarbeitung. Diese Systeme nutzen klassische Softwarearchitektur – Libraries, APIs, Jobs und Pipelines.
Der Agent kommt erst ins Spiel, wenn Interpretation oder Entscheidung notwendig wird: passende Tools auswählen, Workflows zusammenstellen, Vorschläge generieren, Änderungen prüfen lassen. Hier spielt MCP seine Stärke aus. Ein Agent kann Tools entdecken, Optionen vergleichen und Aktionen vorbereiten. Oft wird zusätzlich ein Preview- oder Approval-Step eingebaut, bevor Änderungen tatsächlich ausgeführt werden.
Was sich aus der Erfahrung ergibt
Die wichtigste Erkenntnis aus der Praxis lautet nicht, dass MCP gescheitert ist. Die Erkenntnis lautet: Nicht jede Integration braucht einen Agenten.
MCP funktioniert besonders gut für Tool Discovery, domänenspezifische Aktionen, Reasoning-basierte Workflows und Systeme mit menschlicher Freigabe. Ein fokussierter MCP-Server – drei Domänen, 10 bis 15 semantische Tools, klare Grenzen – ist oft die bessere Antwort als der Versuch, eine komplette API-Fläche abzubilden. Weniger geeignet ist MCP für hochvolumige Datenoperationen und deterministische Automationen.
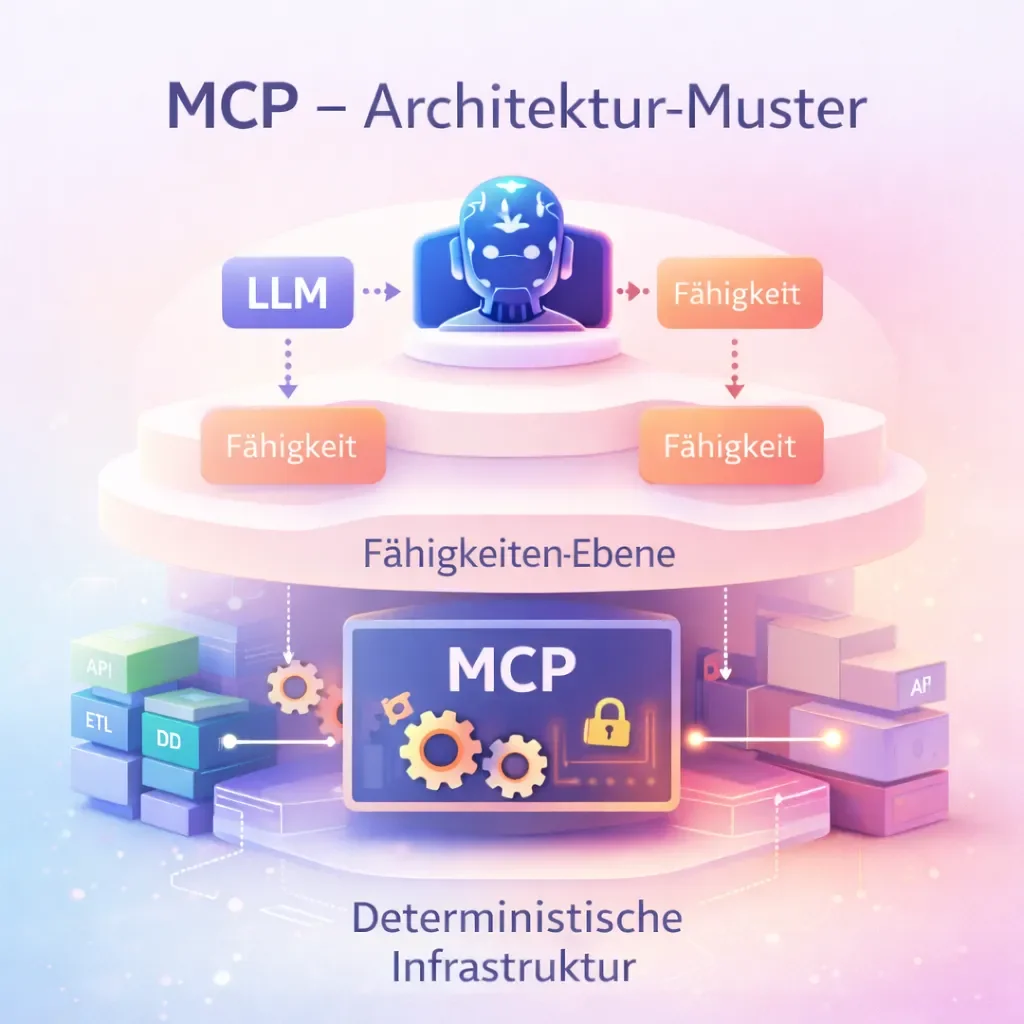
Die 3-Layer-Architektur für Agent-Systeme
In den letzten zwei Jahren hat sich rund um Agent-Systeme eine praktische Erkenntnis durchgesetzt: Das Problem ist selten das Protokoll. Das Problem ist Architekturdisziplin.
Viele frühe Projekte haben einfach ihre komplette API in MCP exportiert. Das funktioniert für kleine Systeme, führt aber schnell zu zwei strukturellen Problemen: unkontrollierbare Tool-Mengen und zu große Kontext-Schemata. Aus der Praxis hat sich deshalb ein Schichtmodell entwickelt.
Layer 1 – Deterministische Infrastruktur
Das ist klassische Softwareentwicklung. Hier liegen APIs, SDKs, Datenbanken, ETL-Pipelines, Batch-Jobs und Automationen. Alles deterministisch und reproduzierbar. Typisierte Schnittstellen, stabile Versionierung, keine LLM-Abhängigkeit, hohe Performance. Beispiele: ERP-API, Payment-API, Datenimporte, E-Commerce-Synchronisationen.
Diese Ebene sollte kein MCP sehen müssen. Sie ist der stabile Maschinenraum des Systems.
Layer 2 – Capability Layer
Hier wird entschieden, was ein Agent überhaupt tun darf. Statt tausende API-Endpunkte freizugeben, definiert man domänenspezifische Fähigkeiten.
Statt createInvoice, updateInvoice, deleteInvoice, addInvoiceItem, updateInvoiceItem wird daraus prepare_invoice_offer oder generate_invoice_from_order. Das Tool kapselt intern API-Aufrufe, Validierungen und Geschäftslogik. Der Agent sieht nur semantische Aktionen. Das reduziert Tool-Komplexität, Tokenverbrauch und Fehlerquellen.
In dieser Schicht sitzt häufig ein MCP-Server oder eine andere Tool-Runtime.
Layer 3 – Agentic Orchestration
Hier arbeitet das LLM. Der Agent versteht Nutzerintention, entscheidet, welches Capability-Tool sinnvoll ist, und kombiniert Aktionen zu Workflows.
Ein Nutzer schreibt: Erstelle ein Angebot für Kunde X basierend auf seiner letzten Bestellung. Der Agent könnte daraufhin die Bestellung suchen, ein Angebot vorbereiten, Änderungen vorschlagen, einen Preview anzeigen und Freigabe einholen. Der Agent orchestriert – aber die eigentliche Logik liegt darunter.
Agent-System Architektur
Warum diese Trennung wichtig ist
Ohne diese Trennung passiert fast immer das Gleiche: Das LLM bekommt Zugriff auf zu viele primitive Tools. updateCustomer, updateCustomerAddress, updateCustomerTax, updateCustomerContact, updateCustomerNotes – der Agent muss dann Geschäftslogik verstehen, Reihenfolge bestimmen und Validierungen erraten. Das ist genau die Art von Problem, bei der LLMs instabil werden.
Tool Sprawl – das MCP-Problem großer Systeme
Ein zweites Problem taucht in vielen MCP-Servern nach einigen Monaten auf. Man nennt es inzwischen häufig Tool Sprawl.
Tool Sprawl entsteht, wenn ein System immer mehr Tools erhält, ohne klare Struktur. Ein realistischer MCP-Server nach einigen Monaten: createInvoice, updateInvoice, createDraftInvoice, createInvoiceFromOrder, createInvoiceFromQuote, addInvoiceItem, removeInvoiceItem, updateInvoiceItem, duplicateInvoice, cancelInvoice, archiveInvoice. Dazu kommen Varianten, neue Parameter, Sonderfälle. Der MCP-Server wächst schnell auf hunderte Tools.
Die Folgen sind dreifach. Erstens Context Inflation: Jedes Tool benötigt Beschreibung und Schema, viele Tools bedeuten große Prompts, höhere Kosten und weniger Kontext für Reasoning. Zweitens Entscheidungsprobleme: Je mehr Tools existieren, desto schwieriger wird die Auswahl für das LLM – das führt zu falschen Toolcalls, inkonsistenten Workflows und unerwartetem Verhalten. Drittens Wartungsaufwand: Der MCP-Server wird selbst zu einer Art API-Layer, Teams müssen Versionierung pflegen, Tools dokumentieren und Kompatibilität sichern. Der Vorteil gegenüber einer normalen API verschwindet.
Drei Regeln gegen Tool Sprawl
Erfahrene Teams nutzen inzwischen drei einfache Regeln.
Capability statt Endpoint. Exportiere keine API-Endpunkte, exportiere Geschäftsaktionen. Also generate_invoice statt createInvoice, addInvoiceItem, setInvoiceCustomer, setInvoiceTax, finalizeInvoice.
Kleine Tool-Sets. Ein Agent sollte idealerweise 10 bis 30 Tools pro Domäne sehen. Nicht hunderte.
Domain-Scope. Tools werden nach Kontext geladen. Ein Vertriebsteam braucht manage_contact, generate_offer, get_forecast. Ein Finance-Agent sieht create_invoice, audit_payment, reconcile_accounts. Diese Trennung ist nicht Luxus – sie ist notwendig für Compliance und Fehlerreduktion.
Der Reifegrad von MCP im Jahr 2026
Nach der ersten Hype-Phase zeigt sich ein klareres Bild. MCP ist kein Ersatz für APIs. Und auch kein universeller Integrationslayer. Es ist eher ein Interface zwischen Reasoning und Softwarefunktionen.
Das funktioniert hervorragend – solange man die Verantwortung klar trennt: Infrastruktur bleibt deterministisch, Geschäftslogik wird gekapselt, Agenten orchestrieren nur noch Fähigkeiten. Wenn diese Struktur eingehalten wird, wird MCP nicht zum Problem. Es wird zu einer effizienten Brücke zwischen Software und KI.
Das neue Agent-Pattern: LLM + Runtime + Sandbox Execution
Die ersten Agent-Systeme waren technisch relativ simpel aufgebaut. Ein Sprachmodell bekam Zugriff auf Tools und rief diese direkt auf: Prompt an das Modell, Modell wählt ein Tool, Tool wird ausgeführt, Ergebnis geht zurück ins Modell. Für einfache Anwendungen funktioniert dieses Muster. Sobald Systeme größer werden, entstehen mehrere Probleme: zu viele Tools, zu große Tool-Schemata, komplizierte Parameter, schwer nachvollziehbare Workflows.
Viele Teams haben deshalb begonnen, ein anderes Architekturprinzip zu nutzen. Dieses Muster taucht inzwischen bei mehreren Plattformen auf, unter anderem bei Cloudflare, OpenAI und verschiedenen Agent-Frameworks.
Warum Tool-Calling allein nicht skaliert
Der klassische Ansatz geht davon aus, dass ein LLM direkt einzelne Tools auswählt. Das Modell muss dabei alle Tools verstehen, Parameter korrekt füllen, die Reihenfolge bestimmen und Fehler behandeln. Bei wenigen Tools funktioniert das zuverlässig. Bei größeren Systemen wird der Agent zum Workflow-Engine – er muss Schleifen, Fehlerbehandlung, komplexe Logik und mehrere API-Aufrufe übernehmen. Dinge, für die Software eigentlich bessere Mechanismen hat. Das führt zu instabilen Agenten.
Code statt Toolcalls
Statt dass ein LLM direkt Tools aufruft, erzeugt es Code oder Skripte, die eine Aufgabe lösen. Dieser Code wird anschließend in einer kontrollierten Umgebung ausgeführt.
Das Modell orchestriert weiterhin den Prozess, aber die tatsächliche Ausführung übernimmt eine Runtime. Die Runtime ist die Brücke zwischen LLM und System – sie übernimmt Ausführung von Code, Zugriff auf APIs, Fehlerbehandlung, Logging und Sicherheitskontrollen. Typischerweise stellt sie bestimmte Bibliotheken bereit: API-Clients, Datenbankzugriff, Hilfsfunktionen. Der Agent generiert dann Code, der diese Bibliotheken verwendet.
const invoice = client.invoices.create(...)
client.invoices.send(invoice)Warum eine Sandbox notwendig ist
Wenn ein Modell Code erzeugt, entsteht ein offensichtliches Risiko: Der Code könnte unerwartete Dinge tun. Deshalb läuft die Ausführung normalerweise in einer Sandbox. Sie sorgt dafür, dass der Code isoliert läuft, nur bestimmte APIs erreichbar sind, Zeit- und Speicherlimits existieren und keine unerlaubten Aktionen möglich sind. Typische Sandbox-Mechanismen sind Container, serverseitige Worker-Runtimes, eingeschränkte Interpreter und WebAssembly-Umgebungen. Die Umgebung kann jederzeit beendet werden, ohne das restliche System zu gefährden.
Weniger Tool-Komplexität
Dieses Pattern reduziert ein zentrales Problem früher Agent-Systeme. Statt hunderte Tools und riesige Tool-Schemas braucht der Agent nur eine Runtime, einige Bibliotheken und Beispielcode. Das reduziert den Kontextbedarf erheblich. Der Agent arbeitet dann nicht mehr mit vielen Tools, sondern mit einer kleinen Programmierumgebung.
Ein praktischer Ablauf: Ein Nutzer sagt Erstelle ein Angebot für Kunde Müller basierend auf seiner letzten Bestellung. Der Agent generiert einen Plan – Kunde suchen, letzte Bestellung laden, Angebot erzeugen, Preview erstellen – und die Runtime erhält ein Skript:
const customer = client.customers.find("Müller")
const order = client.orders.last(customer.id)
const offer = client.offers.createFromOrder(order)
preview(offer)Die Runtime führt das aus und gibt das Ergebnis zurück. Der Agent entscheidet anschließend, wie es weitergeht.
Warum dieses Pattern stabiler ist
Der entscheidende Unterschied liegt in der Verantwortung. Beim klassischen Tool-Calling muss das Modell jeden API-Aufruf einzeln orchestrieren. Beim neuen Pattern übernimmt die Runtime Programmlogik, Fehlerbehandlung, Wiederholungen und Sequenzen. Das Modell konzentriert sich nur noch auf Planung, Interpretation und Entscheidung. Das macht Agent-Systeme deutlich robuster.
Was das für MCP bedeutet
Auch für MCP-Systeme hat dieses Pattern eine Konsequenz. Ein MCP-Server muss nicht mehr jede Funktion als Tool exportieren. Stattdessen kann er Bibliotheken bereitstellen, Capability-Funktionen anbieten und eine Runtime orchestrieren. Der Agent nutzt dann eine Mischung aus Code, wenigen Tools und Runtime-Funktionen. MCP bleibt dabei eine wichtige Schnittstelle für Discovery und Capabilities. Aber die eigentliche Ausführung wandert zunehmend in Runtimes und Sandboxes.
Die Entwicklung der Agent-Architektur
Wenn man sich Agent-Systeme als Evolution anschaut, ergibt sich eine klare Linie.
Diese dritte Phase beginnt gerade, sich als Standardarchitektur herauszubilden. Das Modell bleibt das Gehirn des Systems. Aber die eigentliche Arbeit übernimmt wieder Software.
Wer MCP von den Grundlagen bis zur eigenen Implementierung strukturiert durcharbeiten möchte, findet auf learn.casoon.dev einen Kurs dazu.